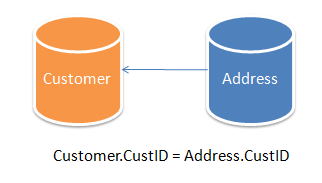
Activity Based Cost and Data Quality: Codependent Initiatives? Summary Activity Based Costing, or ABC, is an exercise where costs are assigned to business activities required to support critical business operations. While it is often used in support of a business process redesign (BPR) effort, it can also serve an important role in data quality (DQ) initiatives. In order to conduct a data quality initiative, a significant investment is required. ...